About Xfce...
What is Xfce?
The people not around in Linux/BSD ecosystem might not know the role of Xfce. To understand it in proper terms, it is a lightweight Desktop Environment designed for Unix-like operating systems and can be installed and used on Linux and BSD. It is one of the lightest, fastest and low on system resources desktop environments.
What is a Desktop Environment?
It is an ecosystem of different software components to interact with the OS. You have a kernel, take Linux Kernel, and you want to access the kernel (which is technically what you’re doing), but, you cannot directly interact with the kernel or directly make sense of most of the things unless you understand the Kernel properly. If you are an everyday, user, you need an interface which can provide you with information and options to interact with the Kernel. There are two ways to do it, one is by using command-line interfaces (think, terminals, more specifically, TTY) or, graphical user interface which is mostly called desktop environment. Actually, Desktop environments not just provide graphical user interface but, do provide functionalities/components/tools which can make working with the Kernel easier.
What constitutes a Desktop Environment?
To be a Desktop environment, it must provide all the basic features required in some form of GUI. The journey starts from user being able to log in, to user being able to create/edit files, and user being able to install other software and use them properly. Desktop Environment, actually, is a collection of software which interoperates with each other to provide the seamless experience. In the core level of things, the Desktop environment contains, a window manager, a desktop manager, a user session/login manager, a power manager, a file manager, a sound/network manager and other individual components. When, you use a desktop environment, you don’t think of these individual things, rather, you think of the collective environment as, all of these interact with each other to provide a unified interface for the user.
What happens when a Computer starts up?
Let’s assume the computer is using some Linux distros, and let us assume, it has Xfce already installed and is using GRUB bootloader. So, what happens when you power on the Computer?
First, you come to the bootloader and, according to our assumption, the GRUB bootloader from which you can select your installation and also, can choose the version of Linux Kernel to boot to. After picking the Kernel version, you are then dropped to a Login Manager or Display Manager. Login Manager provides a user interface and contains a login daemon and can track user sessions. Login Manager isn’t a requirement, as, you can start a Xfce4 session by logging into the TTY interface and can start xfce4 (as, Xfce is using major version 4 now, so it is, xfce4), but, having it makes tracking sessions easier and simple. After logging in, you drop into the Xfce4 desktop environment.
Okay, so I logged into Xfce. What happens next?
So, if you are logged into Xfce, you might see it’s wallpaper, panel, desktop icons, etc. like the image below. 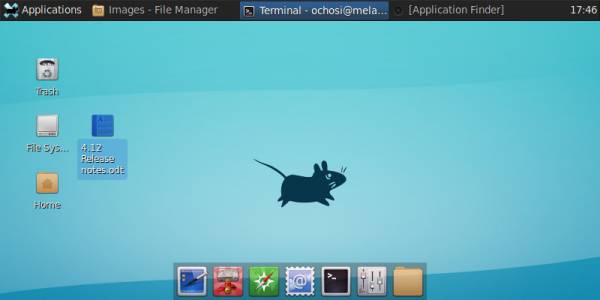 Image src: https://docs.xfce.org
Image src: https://docs.xfce.org
Internally, what happens while loading all this is in the following steps:
Xfce session manager is activated and starts its startup process. Since, this session manager has to save the state of the desktop and restore it during startup, this is checked.
Start of Xfce core components, Xfce core components like xfce4-power-manager, xfce4-session, xfce4-settings, xfdesktop, xfwm4, etc.
It, then, also checks previously saved sessions of applications and loads them if they are saved.
It then, also, starts applications/commands configured to auto-start during login. These can be some commands or some application to kick off.
Then, Xfce components like panel, desktop icons, wallpaper, themes and other configurations start loading.
And finally, user-specific settings kept in specific files are applied. E.g., keyboard mappings kept in .Xmodmap file is applied.
This is all for Part 1 of About Xfce. In the future parts, we will delve into its core components, try to understand how functionalities like power-management, etc. work by visiting the code and I will also, write about the workflow for submitting MRs to Xfce components.

 OpenAI. (2024). ChatGPT [Large language model]. /g/g-2fkFE8rbu-dall-e
OpenAI. (2024). ChatGPT [Large language model]. /g/g-2fkFE8rbu-dall-e (Calvin and Hobbes, Bill Watterson. Retrieved from:
(Calvin and Hobbes, Bill Watterson. Retrieved from: 